강화학습 정리 - Finite Markov Decision Processes
31 Jan 2019 | 강화학습 RL3. Finite Markov Decision Processes
이번 챕터에서는 앞으로 계속 다룰 finite Markov decision processes (MDPs) 에 대해서 소개한다. 그런데 이전 챕터에서 다룬 bandits problem 과는 다르게, 상황에 따라서 다른 action 을 선택해야 하는 associative task 이다. MDPs는 순차적 의사 결정(sequential decision making)을 하는 고전적인 공식인데, 여기서 선택된 action은 immediate reward 에만 영향을 미치는 것이 아니라, 나중의 상황(situation)이나 state 그리고 future reward 에도 영향을 미친다. 그렇기 때문에 MDPs는 delayed reward 라는 개념을 가지고 있으며, immediate reward 와 tradeoff 해야 하는 필요성도 수반하고 있다. Badit problem 에서는 각 action $a$ 의 value로 $q_*(a)$ 를 estimate했지만, MDPs에서는 action $a$ 와 각 state $s$ 의 value로 $q_*(s,a)$ 를 estimate한다.
The Agent–Environment Interface
MDPs는 상호 작용하며 학습하는 문제를 간단하게 정의한다. 학습과 동시에 의사 결정하는 것을 agent 라고 하며, 이 agent 와 상호작용 하며 agent 의 외부에 존재하는 모든 것을 environment 라고 한다. agen 가 action 을 선택하면 environment 는 새로운 상황(situation)을 제시한다. 또한 environment 는 reward 를 제공하는데, agent 는 이 reward가 최대가 되도록 action 을 선택해 나아가야 한다.
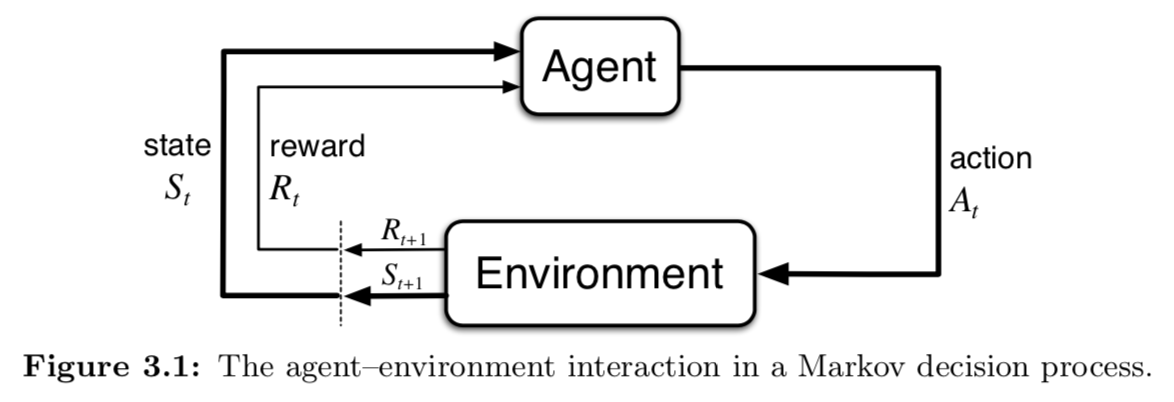
위 그림처럼 각 time step($t$ = 0, 1, 2, 3, …)마다 agent 와 environment 는 상호작용 한다. time step $t$ 에서 agent 는 environment 로부터 state ($ S_t \in \mathscr{S}$ )를 받으며 이를 고려해서 action ($ A_t \in \mathscr{A}(s)$ )을 선택한다. 그리고 한 time step 이후에 action 에 대한 결과로 reward ($ R_{t+1} \in \mathscr{R} \subset \mathbb{R} $)와 새로운 state ($ S_{t+1} $)를 받는다. 이를 순서대로 나타내면 아래와 같다.
\[\begin{align*} S_0, A_0, R_1, S_1, A_1, R_2, S_2, A_2, R_3, ... && (3.1) \end{align*}\]이전 time step 에서 state $s$와 action $a$이 주어졌을 때, $s^\prime$ 와 $r$이 나올 확률은 아래와 같이 표현할 수 있다.
\[\begin{align*} p(s^\prime,r \mid s,a) \doteq \operatorname{Pr}\left\{ S_t=s^\prime, R_t=r \mid S_{t-1}=s, A_{t-1}=a \right\} && (3.2) \end{align*}\]함수 $p$는 MDP의 dynamics를 정의한다. 또한, $p$는 확률 분포이기 때문에 아래와 같이 정의할 수 있다.
\[\sum_{s^\prime \in \mathscr{S}}\sum_{r \in \mathscr{R}}p(s^\prime,r \mid s,a) = 1, \text{ for all }s \in \mathscr{S}, a \in \mathscr{A}(s)\]$S_t$와 $R_t$의 값은 바로 직전의 $S_{t-1}$와 $A_{t-1}$에 의해서만 결정된다. state 는 이전에 발생한 agent 와 environment 의 상호작용에 대한 모든 정보를 내포하고 있어야 하는데, 여기서는 이 state 를 Markov property라고 한다.
다음과 같이 함수 $p$으로부터 environment에 대해서 알고 싶은 정보를 계산할 수 있다.
- state-transition probabilities
- state-action의 reward 기댓값(expected reward)
- state-action-next-state의 reward 기댓값(expected reward)
MDP framework 는 다양한 방법으로 다양한 문제에 적용할 수 있다. 예를 들어서, time step 은 꼭 고정된 간격이 아니여도 되고, action 은 로보트 팔에 적용될 volatage 처럼 low-level 컨트롤 이거나 학교에서 점심을 먹을지 말지에 대한 선택이여도 된다. 또한 state는 sensor에 대한 정보나 방(room)에 있는 물체들에 대한 설명일 수 있다.
MDP framework 는 상호작용으로부터 목표 지향적인(goal-directed) 학습 문제를 추상화한 것이다. 목표 지향적인(goal-directed) 행동을 취하는 어떤 문제에서도, agen와 environment 사이를 오가는 신호를 세가지로 요약할 수 있다. agent 가 선택하는 신호를 action 이라고 하고, 선택이 이루어지는 기본이 되는 신호를 state 라고 하며, agent의 목표인 신호를 reward 라고 한다. MDP framework 가 모든 decision-learning problem 을 표현하기에는 충분하지 않을 수 있으나, 지금까지 상당히 유용하게 사용되어왔다.
물론 특정 state 와 action 은 작업마다 크게 다르며, 어떻게 표현 되느냐에 따라 성능에 크게 영향을 줄 수 있다.
Goals and Rewards
Reinforcement Learning 에서 agent의 목표(goal) 는 environment 로 부터 받는 특별한 신호인 reward 를 공식 하는 것이다. 각 time step 에서 reward 는 단순한 숫자다. 조금 더 간단하게 얘기하면 agent의 목표(goal)는 reward의 총 합을 최대화 하는 것이다. 총 합이라는 것은 즉시 받는(immediate) reward 뿐 아니라, 장기적으로 봤을 때 받을 모든 reward 의 누적값이 라는 의미다.
That all of what we mean by goals and purposes can be well thought of as the maximization of the expected value of the cumulative sum of a received scalar signal (called reward).
reward는 reinforcement learning 에서 가장 두드러지는 특징 중 하나다.
reward 에 대해서 goal 을 공식화하는 것이 한계가 있어 보이지만, 유용하고 넓은 범위에서 사용 가능하다는 것을 증명해왔다. 예를 들어서, 로봇(agent)이 미로를 탈출하는 방법을 학습 시킬때 time step 마다 -1 reward를 주었더니 이 agent는 더 빨리 탈출 하는 방법을 학습했다. 또한 재활용 로봇이 빈 캔을 찾고 수집하는 방법을 학습할 수 있도록 캔을 수집할 때마다 +1 reward를 주어서 학습시키기도 했다.
위의 예에서 보면, agent 는 항상 reward 를 최대화 하기 위해서 학습한다. 만약 agent 가 우리가 원하는 것을 학습하기 원한다면 agent 가 reward 를 최대화 하면서 목표(goal)를 달성할 수 있도록 reward를 제공해야 한다. 따라서 우리가 설정한 reward 는 달성하고자 하는 목표(goal)을 확실하게 가리키도록 해야 한다. Reward 는 agent 와 ‘how’ 가 아닌 ‘what’ 을 communication하는 방법이다.
Returns and Episodes
agent 의 목표는 장기적으로 누적은 reward 를 최대화 하는 것이다. 바로 이 누적된 reward 를 $G_t$ 로 아래와 같이 표현할 수 있다. 이 값을 expected return 이라고 한다.
\[\begin{align*} G_t \doteq R_{t+1} + R_{t+2} + R_{t+3} + \dots + R_T && (3.7) \end{align*}\]위 식에서 $T$를 final time step 이라고 한다. agent-envirionment 사이에서 이뤄지는 상호작용을 episode 개념으로 나눌 수 있다. 이 episode 는 마치 게임에서 한 번 플레이 하는 것과 같은데, 여기서 final time step의 개념이 있는 것은 자연스러운 접근이다. 또한, 각 episode 에서 마지막 state 를 terminal state 라고 한다. episode 가 게임에서 승패와 같이 특정 결과로 끝나더라도 다음 episode 는 이전의 결과와 상관없이 새로 시작된다. 이런 episode로 이루어진 task를 episodic task 라고 한다. episodic task 에서 terminal state의 존재 여부에 따라서 state set 을 아래와 같이 구분한다.
- $\mathscr{S}$ : terminal state 가 포함되지 않는 모든 state set
- $\mathscr{S}^+$: terminal state 이 포함된 모든 모든 state set
반면에 하나의 episode 가 끝나지 않는 경우가 있는데. 이를 continuing task 라고 한다. 이런 경우 final time step 은 $T=\infty$로 무한이기 때문에, 최대화 하려고 했던 return 식 (3.7)에 문제가 생긴다. 그렇기 때문에 앞으로 다른 return 식을 사용한다. 여기에 discounting 라는 컨셉이 추가된다.
\[\begin{align*} G_t \doteq R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + \dots = \sum_{k=0}^\infty \gamma^kR_{t+k+1} && (3.8) \end{align*}\]- $\gamma$: discount rate ($ 0 \le \gamma \le 1 $)
discount rate 는 미래(future) reward 의 현재 가치을 정의한다. 미래 시점인 $k$ time step 에서 받을 reward 의 현재 가치는 $\gamma^{k-1}$ 배 만큼 줄어든다. 만약 $\gamma < 1$ 이면 (3.8) 식은 finite value 를 가지게 될 것이고, $\gamma = 0$이라면 agent 는 즉시 받을(immediate) reward $R_{t+1}$ 만 고려해서 action $A_t$를 선택할 것이다. 하지만 이렇게 immediate reward 만 고려해서 action 을 선택한다면 전체 return 값은 감소할 수 있다. $\gamma$ 가 1에 가까울 수록 전체 return 은 future reward 를 더 많이 수용한다. 이는 agent 가 미래에 받을 reward 를 신뢰한다고 볼 수 있다. 식 (3.8)은 아래와 같이 전개될 수 있다.
\[\begin{align*} G_t &\doteq R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + \gamma^2R_{t+4} +\dots \\ &= R_{t+1} + \gamma (R_{t+2} + \gamma R_{t+3} + \gamma^2 R_{t+4} + \dots) \\ &= R_{t+1} + \gamma G_{t+1} & (3.9) \end{align*}\]return 식 (3.8) 에서 만약 reward 가 0이 아니고 $\gamma < 1$ 이라면 식(3.8)은 finite 하다. 예를 들어서 reward 가 1이라고 가정하면 return 은 아래와 같다.
\[G_t = \sum_{k=0}^\infty \gamma^k = \frac{1}{1 - \gamma}\]Unified Notation for Episodic and Continuing Tasks
이전 섹션에서 agent-environment 상호작용이 일련의 분리된 episode 로 나눠지는 episodic task 와 그렇지 않은 continuing task 에 대해서 알아봤다. 앞으로 이 두 종류의 task 에 대해서 다룰 것이기 때문에, 두 가지를 모두 정확하게 표현할 수 있는 하나의 표기법(notation)을 정의하는 것이 유용하다.
원래는 episodic task 를 더 정확하게 표현하기 위해서 추가적인 notation 이 필요하다. 왜냐하면 여러개의 연속적인 episode 을 표현해야 할 수도 있기 때문이다. 이 episode 와 time step 둘 모두 고려했을 때 episode $i$ 에서 time step $t$ 일 때 state를 $S_{t,i}$ 로 나타낼 수 있다. 다른 것들도 마찬가지로 $A_{t,i}$, $R_{t,i}$, $\pi_{t,i}$, $T_{i}$, 등으로 나타낼 수 있다. 그러나 여기서는 대부분의 경우 episode를 구분할 필요가 없기 때문에 단일 episode 만 고려할 것이기 때문에 $S_{t,i}$ 대신에 $S_t$ 을 사용할 것이다.
episodic task 와 continuing task 는 episode 의 종료 시점을 고려하면 통합 될 수 있는데 그림으로 나타내면 아래와 같다.
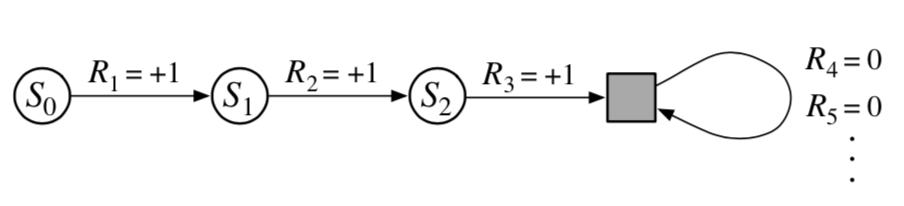
위 그림에서 네모 모양은 episode 의 마지막에 해당하는 special absorbing state 이다. $S_0$ 에서 시작해서 연속적인 reward +1, +1, 0, 0, 0, … 를 받는데, 모두 더하면 $T=3$ 이거나 $T=\infty$ 이더라도 똑같은 reward 를 얻는다. discount rate 를 적용해도 마찬가지다. 식으로 나타내면 아래와 같이 나타낼 수 있다. 앞으로는 아래 식을 계속 사용한다.
\[\begin{align*} G_t \doteq \sum_{k=t+1}^T \gamma^{k-t-1}R_k && (3.11) \end{align*}\]Policies and Value Functions
거의 모든 reinforcement learning 알고리즘은 value function 을 estimating 하는 것을 포함한다. 이 value function 은 agent 가 주어진 state 에 있는 것이 얼마나 많은 expected return 을 받을지 estimate 한다. 그리고 agent 가 주어진 state 에서 선택한 action 이 얼마나 많은 expected return 을 받을지 estimate 하는 것을 action-value function 이라고 한다.
물론, expected reward 는 agent 가 어떤 action 을 선택해 나아가냐에 따라 달려 있다. 그렇기 때문에 value function 은 정책(policy) 이라고 하는 action 을 선택하는 방법에 영향을 받는다.
policy는 state 와 action의 선택 확률을 맵핑한다. agent 가 time $t$ 에서 policy $\pi$ 를 따른다면, $S_t = s$ 가 주어졌을 때 $A_t = a$ 일 확률을 $\pi(a \mid s)$ 로 나타낼 수 있다.
MDPs 에서 policy $\pi$ 를 따르는 value function 와 action value function 을 아래와 같이 정의할 수 있다.
- state-value function for policy $\pi$
- action-value function for policy $\pi$
위 두 value function 값은 경험을 통해서 측정할 수 있다. 예를 들어서, agent 가 policy $\pi$ 를 따르는 상황에서 무한히 각 state 에서 value 의 평균을 구한다면 $v_\pi(s)$에 수렴(converge) 한다. 그리고 마찬가지로 $q_\pi(s,a)$ 도 수렴한다. 실제 return 을 매우 많이 샘플링해서 평균을 구하는 방법으로, Monte Carlo method 라고 한다.
Reinforcement learning 과 dynamic programming 에서 value function 의 근본적인 성질은 식(3.9) 처럼 재귀적인 관계(recursive relationship) 를 충족 시킨다는 것이다.
\[\begin{align*} v_\pi(s) &\doteq \mathbb{E}_\pi\left[G_t \mid S_t=s \right] \\ &= \mathbb{E}_\pi \left[R_{t+1} + \gamma G_{t+1} \mid S_t=s \right] & (by (3.9))\\ &= \sum_a \pi(a \mid s) \sum_{s^\prime}\sum_r p(s^\prime,r \mid s,a) \left[ r + \gamma \mathbb{E}_\pi \left[G_{t+1} \mid S_{t+1} = s^\prime \right] \right] \\ &= \sum_a \pi(a \mid s) \sum_{s^\prime, r} p(s^\prime,r \mid s,a) \left[ r + \gamma v_\pi(s^\prime) \right], \text{for all } s \in \mathscr{S}, & (3.14) \end{align*}\]식 (3.14)는 $v_\pi$에 대한 Bellman equation 이다. 이것은 state 의 value 와 다음 state 의 value 에 대한 관계를 표현한다. 아래는 그림으로 나타낸 것이다.
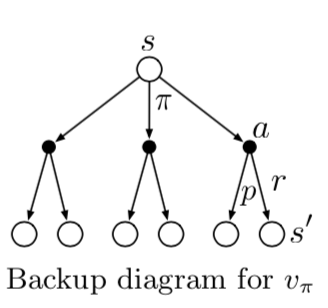
하얀 원은 state 이고 검정 점은 action 을 의미한다. 제일 위에 있는 state $s$ 에서 시작하여, agent는 policy $\pi$ 를 따라서 세 개의 action 중 하나를 선택한다. 그러면 environment 는 dynamics 함수 $p$에 따라서 reward $r$ 과 다음 state $s_\prime$ 를 준다. Bellman Equation(3.14)은 발생될 확률을 가지는 모든 가능성에 대한 평균이다. 처음 state 의 value 는 다음 expected state 의 (discounted) value 와 그에 따른 reward 의 합과 같다.
Reinforcement learning method 에서 심장이라고 할 수 있는 update 혹은 backup 연산을 나타내기 때문에, 위 다이어그램을 backup diagram 이라고 한다.
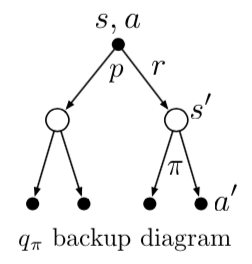
$q_\pi(s, a)$에 대한 Bellman equation을 backup digram으로 나타내면 아래와 같다.
Optimal Policies and Optimal Value Functions
Reinforcement learning 문제를 해결한다는 것은 장기적 관점에서 가장 많은 reward 를 얻을 수 있는 policy 를 찾는 것이다. 만약 모든 state 에서 $\pi$ 의 expected return 이 $\pi^\prime$ 보다 같거나 더 크다면, policy $\pi$ 가 policy $\pi^\prime$ 보다 더 잘 정의된 것이다. 다시 말해서 $ s \in \mathscr{S}$ 에서 $v_\pi(s) \geq v_{\pi^\prime}$ 이라면 $\pi \geq \pi^\prime$ 이다. 이중에서 다른 모든 policy 보다 제일 나은 policy 를 optimal policy 라고 하며, $\pi_*$ 로 표기한다. 그리고 이 optimal policy 를 따르는 state-value function 을 optimal state-value function 이라고 하며, action-value function 을 optimal action-value function 이라고 한다.
- optimal state-value function
- optimal action-value function
$q_*$ 를 $v_*$ 에 대한 식으로 아래와 같이 정의할 수 있다.
\[\begin{align*} q_*(s,a) = \mathbb{E} \left[ R_{t+1} + \gamma v_*(S_{t+1}) \mid S_t=s, A_t=a \right] \end{align*}\]$v_*$는 policy 에 대한 value function 이기 때문에, Bellman Equation (3.14) 의 조건에 대해 일관성을 가져야 한다. 그러나 optimal value function 이기 때문에 특정한 policy 와 상관 없는 식을 가져야 한다. 이를 Bellman optimality equation 이라고 한다. 직관적으로 말하면, Bellman optimality equation 은 optimal policy 를 따른 state 의 value 와 가장 좋은 action 을 선택했을 때 받는 expected return 은 같다는 사실을 표현한다.
\[\begin{align*} v_*(s) &= \underset{a \in \mathscr{A}(s)}{\text{max}} q_{\pi_*}(s,a) \\ &= \underset{a}{\text{max}} \mathbb{E}_{\pi_*} \left[ G_t \mid S_t = s, A_t = a \right]\\ &= \underset{a}{\text{max}} \mathbb{E}_{\pi_*} \left[ R_{t+1} + \gamma G_{t+1} \mid S_t = s, A_t = a \right] & (by (3.9))\\ &= \underset{a}{\text{max}} \mathbb{E} \left[ R_{t+1} + \gamma v_*(S_{t+1}) \mid S_t = s, A_t = a \right] & (3.18)\\ &= \underset{a}{\text{max}} \sum_{s^\prime, r}p(s^\prime, r \mid s, a) \left[ r + \gamma v_*(s^\prime) \right] & (3.19) \end{align*}\]위 식에서 마지막 두 방정식은 $v_*$ 에 대한 Bellman optimality equation 의 두가지 형태이다. $q_*$ 에 대한 Bellman optimality equation 은 다음과 같다.
\[\begin{align*} q_*(s,a) &= \mathbb{E} \left[ R_{t+1} + \gamma \underset{a^\prime}{\text{max}}q_*(S_{t+1}, a^\prime) \mid S_t=s, A_t = a \right] \\ &= \sum_{s^\prime, r}p(s^\prime, r \mid s, a) \left[ r + \gamma \underset{a^\prime}{\text{max}}q_*(s^\prime, a^\prime)) \right] & (3.20) \end{align*}\]아래 backup diagram 은 $v_*$ 와 $q_*$ 에 대한 Bellman optimality equation 을 시각적으로 보여준다. 이 backup digram 은 agent 가 max 를 선택하는 부분인 호(arc)를 제외하면 앞의 $v_\pi$ 및 $q_\pi$ 와 같다. 왼쪽은 식 (3.19)을 보여주고, 오른쪽은 식 (3.20)을 보여준다.
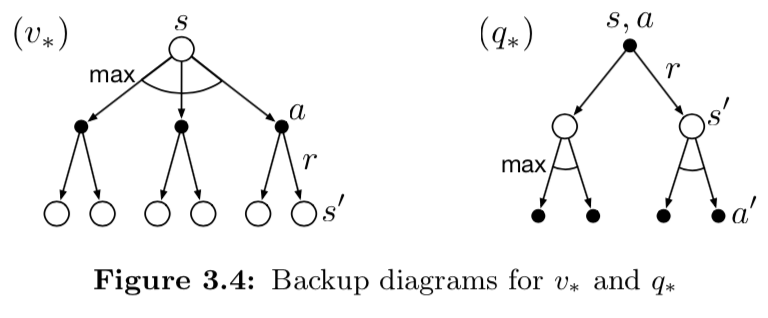
만약 $v_*$ 를 알고 있다면 optimal policy 를 찾는 건 상대적으로 쉽다. 각 state $s$ 에서 Bellman optimality equation 의 최대 값을 얻을 수 있는 action 이 하나 이상은 있을 것이다. 이 action 에 0이 아닌 확률이 부여된 policy 가 optimal policy 이다. 이것을 one-step search 로 생각할 수 있는데, one-step search 후에 선택한 action 이 optimal action 이다. 장기적인 관점에서 기대되는 최적의 반환 값(optimal expected long-term return)인 $v_*$ 은 각 state 에서 사용된다. 그러므로 one-step-ahead search 는 long-term optimal action 을 찾는다고 볼 수 있다.
$q_*$ 가 있으면 optimal action 을 찾기가 더 쉽다. $q_*$ 가 있으면 agent는 one-step-ahead search를 하지 않아도 된다. 왜냐하면 모든 state $s$에서 $q_*(s,a)$ 가 가장 큰 action $a$ 를 찾으면 되기 때문이다. action-value function 은 모든 one-step-ahead search 의 결과를 보관(cache)한다. 이것은 각 state-action pair 에서 바로 사용할 수 있는 값으로써 optimal expected long-term return 를 제공한다.
명시적으로 Bellman optimality equation 을 푸는 것은 optimal policy 를 찾기 위한 또 다른 방법이다. 이것은 곧 reinforcement learning 문제를 해결하는 것이다. 그러나 이 방법은 거의 유용하지 않다. 이 방법은 실제 문제에서는 거의 얻을 수 없는 세가지 가정을 충족해야 한다.
- Environment 의 dynamics 에 대해 정확하게 알고 있어야 한다.
- 연산에 필요한 충분한 resource 가 있어야 한다.
- Markov property 를 만족해야 한다.
그러나 우리가 관심을 가지고 있는 문제들은 거의 위 조건들을 충족하지 않는다. 예를 들어서 backgammon 게임에서 1번과 3번 은 충족하지만 2번 조건에서 문제가 생긴다. 왜냐하면 backgammon 게임은 거의 $10^{20}$ 의 state를 가지는데, 요즘 가장 빠른 컴퓨터를 사용하더라도 $v_*$ 이나 $q_*$ 를 계산하기 위해서는 수천년이 걸리기 때문이다. 그렇기 때문에 reinforcement learning 에서는 일반적으로 approximate solution 을 찾아야 한다.
다양한 decision-making 문제는 Bellman optimality equation 을 근사(approximately)하는 방법으로 해결한다고 볼 수 있다. Dynamic programming 은 Bellman optimality equation 에 조금 더 관련되어 있다. 많은 reinforcement learning 문제는 사전 정보가 아닌 실제 경험을 통해서 Bellman optimality equation 을 근사적으로(approximately) 해결하는 것으로 이해할 수 있다.
Optimality and Approximation
지금까지 optimal value function 과 optimal policy 에 대해 정의했다. 분명 agent 는 optimal policy 를 매우 잘 학습할 수 있지만, 이는 현실에서 매우 드물게 이루어진다. 우리가 관심 있어하는 과제에서 optimal policy 를 구하기 위해서는 극도로 많은 계산량이 필요하다. 또한 environment 의 dynamic 에 대해 정확하게 알고 있더라도 Bellman optimality equation 으로 부터 optimal policy 를 계산하는 것은 간단하지 않다.
또한 가용 가능한 메모리 에도 한계가 있다. 다양한 문제들을 해결하기 위해서는 매우 많은 메모리가 필요하다. 각 array 나 table 을 사용해서 해결할 수 있는 작은 문제들이 있는데, 이런 경우를 tabular case 라고 하고 여기에 대응하는 식을 tabular method 라고 한다. 그러나 우리가 관심있어하는 많은 문제들은 table 에 담을 수 있는 정보보다 훨씬 많은 state 들이 존재하다. 이런 경우 좀 더 간결한 매개 변수화된(parameterized) 함수를 이용하여 근사화(approximated) 해야 한다.
In these cases the functions must be approximated, using some sort of more compact parameterized function representation.
Summary
Reinforcement learning 은 목표를 달성하기 위해서 어떻게 행동해야 하는지 배우는 것이다. 그리고 이 학습은 상호작용으로부터 이루어진다. agent 와 environment 는 연속적인 이산 time step 으로 부터 상호작용 한다. action 은 사용자가 선택하는 것이고, state 는 action 을 선택하기 위한 기반이 된다. 그리고 reward 는 그 선택을 평가하는 기준이다. agent 의 외적인 요소들은 불완전하게 제어가 가능하지만, 완벽하게 알려지지 않았을 수도 있다. policy 는 agent 가 action 을 선택하는데 필요한 각 state 에 대한 확률적인 규칙이다. 그리고 agent 의 목표는 앞으로 받을 reward 의 총 합을 최대화 하는 것이다.
Reference
- [Reinforcement Learning: An Introduction - Richard S. Sutton a
Comments